
引言
在准备开始学习《机器学习》这本经典入门书籍之前,首先,需要重新明确一下学科的宗旨,就比如本人之前接触较多的化学学科宗旨在于探索和发现基于原子的分子乃至于基于分子的超分子层面的变化规律,其中无非是变化,即反应,的参与双方(反应物与产物),变化的条件以及变化的过程。
而这所有的一切都是从“何为变化?”这个问题引申开去,不同的二级学科分工也不过是对上述的几个角度中直接或者间接地提供了具体的科学研究实践。有机化学和无机化学的区分主要在于参与双方的化合物类型归属上,不过随着学科的发展,这种人为设定的二级学科界限势必阻挡不了学科宗旨本身的归类方式;分析化学不过是对变化的三方面的监测,为深入研究提供信息反馈;物理化学最经典的热力学与动力学也就是对于变化这个问题本身二次思考,随后以时间作为一个分割的角度来展现这两种思维考察变化过程的本质区别。以上的具体学科举例不代表每个二级学科只有这个方面的思考,这是不尽然的,二级学科的交叉性并非是人类简单的设限归纳就能够去消解的,至少对于化学而言是这样子的。
尽管有人会说,化学的宗旨更应该在于对制药、新材料研发以及化工生产的基础学科支持,诚然应用层面的利国利民没有问题,但是如果站在学科本身的纯粹目的来看,应用层面的延展很多时候是基础学科研究的无心插柳。至少,在这个聚焦于学科宗旨的话题上,本人目前更倾向于从一个纯粹的角度去体会学科自身的一个思考方式。应用层面的思考固然重要,但是不在这次探讨的范围内。
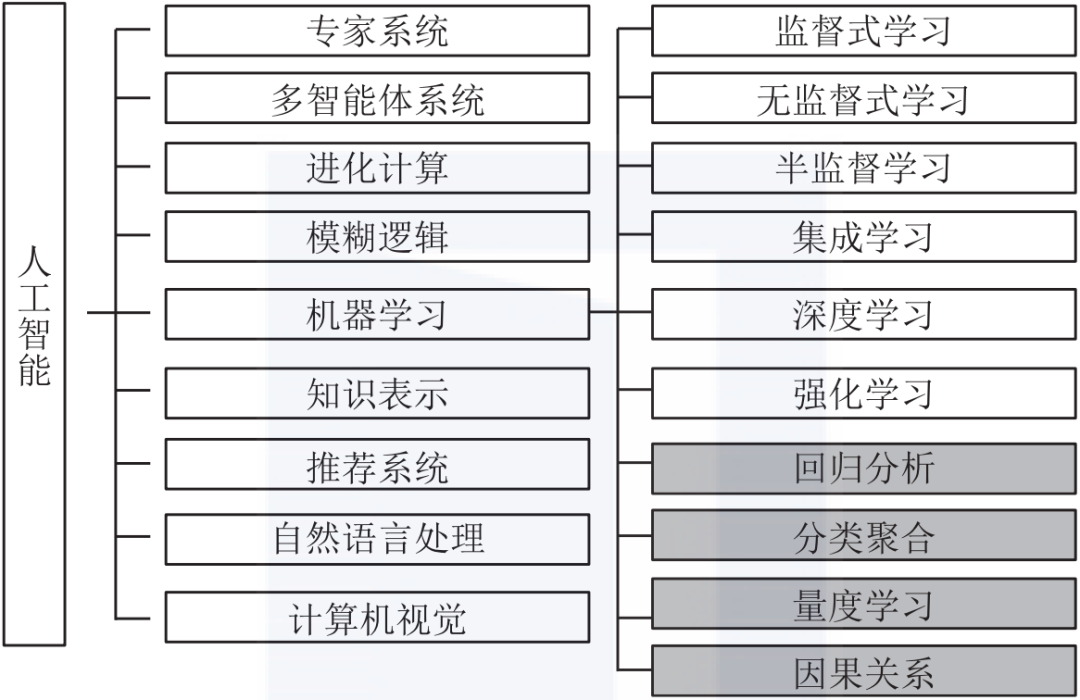
既然能够以这种方式考察本人比较熟悉的化学,那么也希望用同样的思维方式来审视一下“人工智能”这一门学科(如1-图1),至少在本人看来机器学习(machine learning)属于人工智能(artificial intelligence)的二级学科,并不足以直接拿来与化学相提并论。单纯从图中的二级学科分类来看,本人姑且人为人工智能的学科宗旨在于“何为智能?”,也许是“智能”本身的定义与考察,也许是到达所谓“智能”这个状态的方式与过程,同样也有是什么事物要去达到这种“智能”状态的探讨,这里暂且认为“智能”是一种状态,因为从比较笼统的角度看,即使在过程中体现出了“智能”,也能够算得上达到过“智能”的状态。
在明确了作为父级学科的人工智能的学科宗旨之后,“机器学习作为一门致力于研究如何通过计算的手段利用经验改善系统自身性能的学科”的定义就变得十分清晰了。原文中并没有在定义中明确就是计算机系统,考虑到人工智能以及机器学习与计算机科学的紧密关联性,一般会假定探讨的系统限制于计算机系统,不过就本人看来,这个所谓的”学习“可以是一个非常泛化的概念。正如人接触形形色色的事物的过程中积累经验并以此处理新的情况,计算机的“经验”则是人为投喂的“数据”,也正如人在经验积累中会自然而然形成一套基于以往经验的思想行为模式,计算机也可以通过“学习”这些投喂“数据”来形成一套它的思维行为模式,即“模型”(model),人类的经验-模式过程是十分复杂多样的,如果我们希望计算机也同样达到具有人类一样“智能”的效果,即一种通过学习总结过去的经历以处理未来不确定事物的能力,那么需要去人为的给予计算机一条条数据-模型的实现过程,即“学习算法”(learning algorithm)。如果说,自然科学追求的是一种解构万物的还原论式的原理与内容,那么机器学习关注的则是如何让系统,尤计算机系统,具有知往事而晓来者能力的经验式的方法与手段。(模型与模式,在某些地方会被认为具有整体与局部的区别,此处暂且忽略这点)
基础概念梳理
- 算法(algorithm):算法是指从数据中学习(learning)或者训练(training)得模型的具体方法。
- 模型(model):算法产出的结果,通常是具体的函数或者可以抽象地当作函数。
- 特征向量(feature vector):数据集(data set)中的示例(instance)或者样本(sample),由于在样本对应的属性(attribute)或特征(feature)张成的属性空间(attribute space)或样本空间(sample space)或输入空间(
)中可以通过具体的样本对应的属性值(attribute value)来确定样本空间中的对应点的坐标,从而这个样本本身可以被看成构成了一个特征向量,属性的数量称为维数(dimensionality)。 - 特征工程:主要是与特征处理相关的工作,一般是在原有特征基础上拓展更多维度的特征。
- 训练集(training set):训练过程中的数据被称为训练数据(training data ),其中每个样本称为一个训练样本(training sample),这些样本组成了训练集。
- 测试集(testing set):用以检验训练结果的测试样本(testing sample)集合。
- 假设(hypothesis)与真相(ground-truth):通过训练得到的模型被看作是对应数据的潜在规律的相关,潜在规律本身被视为真相,而模型责备认为是假设,学习的过程是逼近真相的过程。模型可被看作学习算法在给定数据和参数空间上的实例化,可被称为学习器(learner)。
- 标记空间(lanel space):又称输出空间,建立关于预测(prediction)的模型通常需要训练集中包含了训练样本对应的结果,被称为标记(label),
代表了所有标记的集合,被称为标记空间,通常被视为样本的一部分,完整的样本通常为 。
- 回归(regression):预测值为连续值的学习任务。
- 分类(classification):预测值为离散值的学习任务。有二分类任务(binary classification)与多分类任务(multi-class classification),其中二分类里面分为正类(positive class)与反类(negative class)。
- 聚类(clustering):通过某些特征将训练集中的样本分为不同的“簇”(cluster),对应一些潜在的概念划分,有助于了解数据的内在规律。
- 监督学习(supervised learning)有标记信息的学习任务,典型代表有回归与分类。
- 无监督学习(unsupervised learning):无标记信息的学习任务,典型代表有聚类。
- 泛化(generalization):学习得到的模型适用于新样本的能力。
- 独立同分布(independent and identically distributed, i.i.d.):我们通常假设样本空间中全体样本服从一个未知分布(distribution)
,而用于训练的每个样本都是独立地从这个分布上采样获得的。一般来说训练样本越多,模型针对总样本空间分布 的泛化能力越好。 - 概念学习(concept learning):狭义上的归纳学习(inductive learning),需要从训练数据中学得概念,区别于广义上从样例中学习,泛化性能好与语义明确的概念学习十分困难。
- 假设空间(hypothesis space):所有可能模型的集合,学习模型的过程就是在假设空间中根据要求找到最合适的一个模型。
- 版本空间(version space):在给定的训练数据和假设空间的情况下,所有符合训练数据的假设的集合。版本空间包含了所有能够正确地解释训练样本的模型或假设。
- 归纳偏好(inductive bias):算法在学习过程中对于某种类型假设的偏好。
- 机器学习分类:机械学习、示教学习、类比学习、归纳学习,目前的主流属于归纳学习,即从样例中学习。

